Overview
In this paper, we present ControlSpeech, a text-to-speech (TTS) system capable of fully cloning the speaker's voice and enabling arbitrary control and adjustment of speaking style, merely based on a few seconds of audio prompt and a simple textual style description prompt. Prior zero-shot TTS models and controllable TTS models either could only mimic the speaker's voice without further control and adjustment capabilities or were unrelated to speaker-specific voice generation. Therefore, ControlSpeech focuses on a more challenging new task—a TTS system with controllable timbre, content, and style at the same time. ControlSpeech takes speech prompts, content prompts, and style prompts as inputs and utilizes bidirectional attention and mask-based parallel decoding to capture corresponding codec representations in a discrete decoupling codec space. Moreover, we discovered the issue of text style controllability in a many-to-many mapping fashion and proposed the SMSD module to resolve this problem. SMSD module which is based on Gaussian mixture density networks, is designed to further mix sample style semantic information and generate speech with more diverse styles. In terms of experiments, we open source a controllable model toolkit called ControlToolkit with a new style controllable dataset, some replicated baseline models and propose new metrics to evaluate both the control capability and the quality of generated audio in ControlSpeech. The relevant ablation studies validate the necessity of each component in ControlSpeech is necessary. We hope that ControlSpeech can establish the next foundation paradigm of controllable speech synthesis.
Model Architecture
Figure (a) illustrates the overall architecture of ControlSpeech, which is an encoder-decoder-based parallel disentangled codec generation model. Figure (b) depicts the SMSD module, which alleviates the many-to-many problem in style control by sampling from the style mixture semantic distribution and incorporating an additional noise perturbator. Figure (c) shows the basic disentanglement process of the codec generator. Through masking, the codec can generate discrete codec representations in a fully non-autoregressive manner.
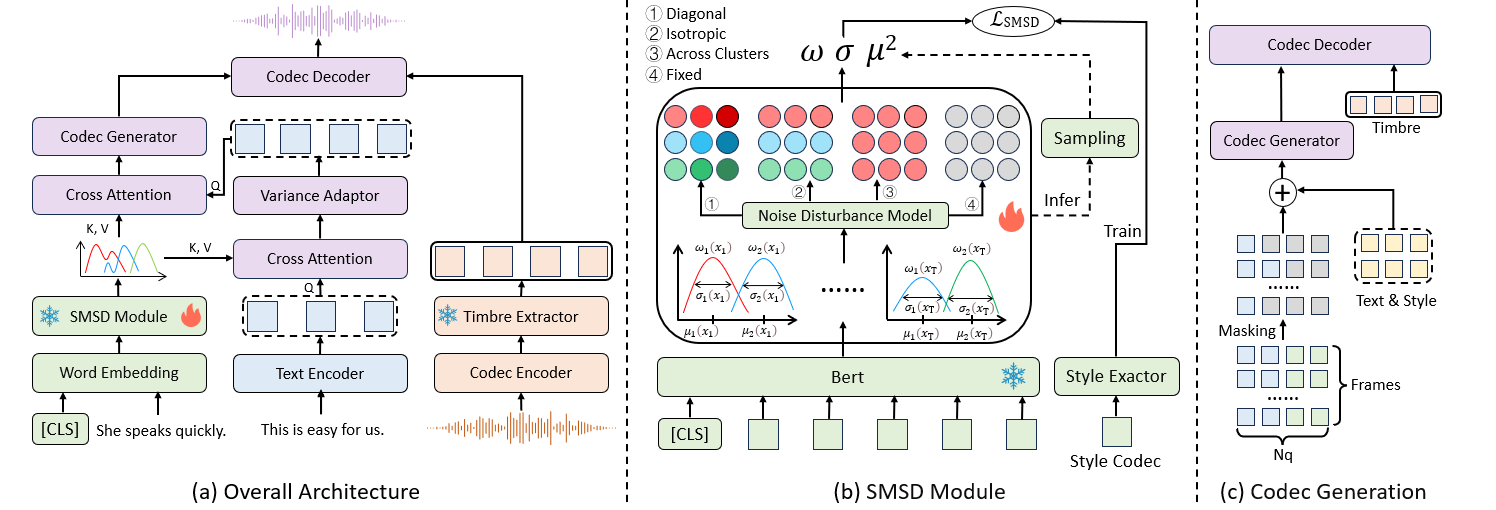 |
Figure.1 The overall architecture of ControlSpeech.
Compare with baselines
We provide a range of audio to exemplify the differences between ControlSpeech and the baseline models (InstructTTS, PromptStyle and PromptTTS).
Content Prompt: He would have withdrawn from the feast had not the noise of voices allayed the smart.
Style Prompt: A young speaker's low-energy, whispered speech is rapid.
Voice Prompt:
| GT(w/o Style) | InstructTTS | PromptTTS | PromptStyle | ControlSpeech(Ours) |
|---|---|---|---|---|
Content Prompt: Yes, captain, maybe so.
Style Prompt: A speaker, maintaining a standard pitch, engages in unhurried speech with a touch of normal energy.
Voice Prompt:
| GT(w/o Style) | InstructTTS | PromptTTS | PromptStyle | ControlSpeech(Ours) |
|---|---|---|---|---|
Content Prompt: He dropped the lighted shaving in a safe spot and put up his hands.
Style Prompt: Speaker's speaking rate is normal, despite speaker's voice's high pitch.
Voice Prompt:
| GT(w/o Style) | InstructTTS | PromptTTS | PromptStyle | ControlSpeech(Ours) |
|---|---|---|---|---|
Content Prompt: He never comes to the pump room, I suppose?
Style Prompt: The speaker's energy is low, yet speaker's whispering speed is ordinary.
Voice Prompt:
| GT(w/o Style) | InstructTTS | PromptTTS | PromptStyle | ControlSpeech(Ours) |
|---|---|---|---|---|
Content Prompt: Fort lyon, colorado territory, december, eighteen seventy one.
Style Prompt: The speaker talks at a moderate speed, neither too fast nor slow.
Voice Prompt:
| GT(w/o Style) | InstructTTS | PromptTTS | PromptStyle | ControlSpeech(Ours) |
|---|---|---|---|---|
Content Prompt: Once Layelah sat for some time silent and involved in thought.
Style Prompt: The speaker's low-pitched voice delivers speaker's message with a moderate level of energy and standard speaking speed.
Voice Prompt:
| GT(w/o Style) | InstructTTS | PromptTTS | PromptStyle | ControlSpeech(Ours) |
|---|---|---|---|---|
Content Prompt: They'd never know I'd regular ran away.
Style Prompt: Speaker's speech maintains a usual pitch as speaker mournfully talks at a regular speed with a touch of standard energy.
Voice Prompt:
| GT(w/o Style) | InstructTTS | PromptTTS | PromptStyle | ControlSpeech(Ours) |
|---|---|---|---|---|
Content Prompt: It looks much better.
Style Prompt: Speaking rapidly in a low pitch, the surprised speaker's energy remains minimal.
Voice Prompt:
| GT(w/o Style) | InstructTTS | PromptTTS | PromptStyle | ControlSpeech(Ours) |
|---|---|---|---|---|
Style control for unseen speakers
We provide a series of audio to demonstrate ContorSpeech's ability to control the style of unseen speakers.
Content Prompt: I was never in the county till my husband brought me here. Mrs Charmond did not care to pursue this line of investigation.
Style Prompt: The pitch of speaker's speech is within the norm.
Voice Prompt: Note that the timbre is derived from GT wav.
| GT wav | Generated wav |
|---|---|
Content Prompt: It is made of silk or cotton.
Style Prompt: The speaker communicates with minimal energy.
Voice Prompt: Note that the timbre is derived from GT wav.
| GT wav | Generated wav |
|---|---|
Content Prompt: She went away without saying any more.
Style Prompt: Speaking at a moderate speed, the speaker engages speaker's audience.
Voice Prompt: Note that the timbre is derived from GT wav.
| GT wav | Generated wav |
|---|---|
Content Prompt: Such conduct didn't speak much for military discipline in those days.
Style Prompt: A speaker with a regular pitch talks swiftly, exuding a touch of moderate energy.
Voice Prompt: Note that the timbre is derived from GT wav.
| GT wav | Generated wav |
|---|---|
Content Prompt: Once upon a time a mouse dwelt in the house of a merchant who owned much merchandise and great stories of monies.
Style Prompt:speaker's pitch is average, even though speaker's energy is low.
Voice Prompt: Note that the timbre is derived from GT wav.
| GT wav | Generated wav |
|---|---|
Control of unseen styles
ControlSpeech supports transforming unseen styles.
Content Prompt: It took her a long time to understand that he had actually spoken them.
Style Prompt:Speaking rapidly, the speaker's voice reverberated powerfully, striking a lower key.
Voice Prompt: Note that the timbre is derived from GT wav.
| GT wav | Generated wav |
|---|---|
Content Prompt: What's to be done?
Style Prompt:The speaker expressed with a sharp clarity, maintaining a steady flow and a low loudness.
Voice Prompt: Note that the timbre is derived from GT wav.
| GT wav | Generated wav |
|---|---|
Content Prompt: "That's right", approved the great Personage, glancing down complacently over his double chin.
Style Prompt:The speaker spoke in a hurried, low murmur, each word soft but fast.
Voice Prompt: Note that the timbre is derived from GT wav.
| GT wav | Generated wav |
|---|---|
Content Prompt: I am safe back again.
Style Prompt:The speaker's intonation, unhurried and barely audible, carried a deep-seated note.
Voice Prompt: Note that the timbre is derived from GT wav.
| GT wav | Generated wav |
|---|---|
Style control for multiple speakers
ControlSpeech can use multiple timbres to correspond to one style.
Content Prompt: The patient and the surgeon are both recuperating from the lengthy operation.
Style Prompt: Her speaking rate is steady, and her contemptuous voice has a high pitch.
| Speakers A | Speakers B |
|---|---|
Content Prompt: The patient and the surgeon are both recuperating from the lengthy operation.
Style Prompt: A scornful woman with a low-pitched voice spoke.
| Speakers A | Speakers B |
|---|---|
Content Prompt: The patient and the surgeon are both recuperating from the lengthy operation.
Style Prompt: In her disdainful normal tone, she spoke rapidly.
| Speakers A | Speakers B |
|---|---|
Content Prompt: The patient and the surgeon are both recuperating from the lengthy operation.
Style Prompt: The contemptuous woman's speech unfolds slowly, with a normal tone.
| Speakers A | Speakers B |
|---|---|
Content Prompt: The patient and the surgeon are both recuperating from the lengthy operation.
Style Prompt: A dismissive woman with a loud voice speaks normally.
| Speakers A | Speakers B |
|---|---|
Content Prompt: The patient and the surgeon are both recuperating from the lengthy operation.
Style Prompt: The contemptuous girl's energy is low, but she speaks with a typical speed.
| Speakers A | Speakers B |
|---|---|